Have you ever wondered why even the most advanced AI models sometimes struggle with non-European languages or take an eternity to load on a mobile device? While we often hear about the massive power of billion-parameter giants, a fascinating shift is happening toward hyper-specialized, tiny models that are quietly solving the world’s most frustrating accessibility gaps.
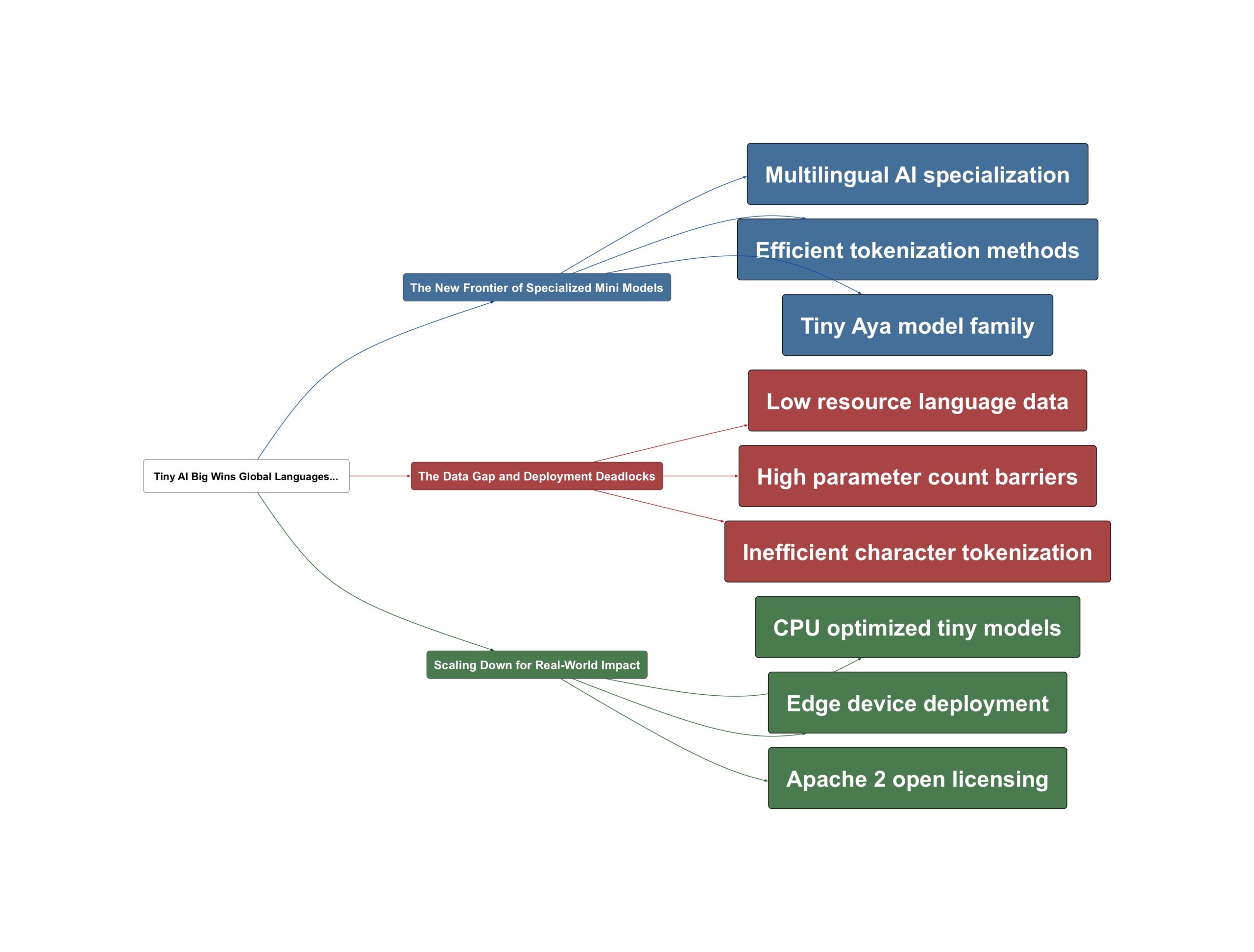
The New Frontier of Specialized Mini Models
In the current landscape of artificial intelligence, we are seeing a move away from the ‘one size fits all’ approach. Large models handle English or French with ease, but the real challenge lies in supporting the thousands of other languages spoken globally. As the industry evolves, specialized families like Cohere’s Tiny Aya are emerging to bridge this gap. These models aren’t just smaller; they are designed with a deep understanding of linguistic nuances that larger, more generalized models often overlook.
A critical part of this evolution involves how models ‘read’ text. Modern stacks, such as Gemma 3, have moved toward massive 250k+ tokenizers that allow for much more efficient processing of diverse scripts. This shift is transformative because it allows a model to understand a language naturally rather than breaking it down into inefficient, tiny fragments. The focus has shifted from raw size to architectural efficiency. According to Sam Witteveen:
The Gemma 3 models were pretty good at multilingual coverage. And that related both to them having better tokenizers… and also just a lot of multilingual data.
— Sam Witteveen
The Data Gap and Deployment Deadlocks
But why is it so hard to get this right? The primary complication is the lack of digital footprints for many cultures. We often rely on Wikipedia for training data, but many languages simply don’t have an active presence there. This creates ‘low resource’ scenarios where the AI has never actually seen the language it is expected to process. Sound familiar? It is the digital equivalent of trying to learn a language without a dictionary.
Furthermore, there is the ‘tokenization tax.’ Older models often processed non-Latin scripts character-by-character, making them slow and expensive. As Sam Witteveen explains:
This basically just means it’s much harder for the model to learn that language if the tokens for that language are basically character by character and occasionally even partial character by character.
— Sam Witteveen
Beyond language, we face a hardware bottleneck. High-quality voice cloning models often sit at 1.7 billion parameters, which effectively rules out running them directly in a web browser or on a basic mobile phone without a powerful GPU.
Scaling Down for Real-World Impact
The resolution to these challenges lies in ultra-lightweight, CPU-optimized models that can live anywhere. Projects like KittenTTS are proving that we can shrink high-performance tools down to under 25 megabytes. This isn’t just a technical feat; it is a democratization of technology. By optimizing for the CPU rather than the GPU, these models can run on edge devices, old phones, and directly in browsers without massive infrastructure costs.
Building on this, the use of open-source frameworks like the Apache 2 license allows developers to integrate these ‘nano’ models into specialized applications without friction. One key insight from Sam Witteveen regarding this trend is:
The thing that I find fascinating here is that these models are small enough that we can probably run them in a browser or run them certainly on a mobile phone without taking up too much space.
— Sam Witteveen
By combining improved tokenization with tiny, efficient architectures, we are finally reaching a point where AI can be truly global and local at the same time.
💡 Key Takeaway: Hyper-specialized tiny models are solving global accessibility and edge deployment challenges.
Video Sources