OpenAI 额度“大放水”:是技术故障还是公关补偿?
就在这两天,OpenAI 的 Codex 用户经历了一场过山车式的体验。前脚刚因为额度像“漏水”一样莫名消耗而在 GitHub 上吵得不可开交,后脚官方就悄悄给全球用户来了一次“额度大重置”。
这事儿挺有意思的。官方一边咬死说“受影响用户太少,不值得搞全球重置”,结果不到 24 小时,大家的进度条全绿了。这种“打脸式”的福利,背后折射出的其实是 AI 巨头在高速增长中,与核心开发者社区之间日益微妙的张力。
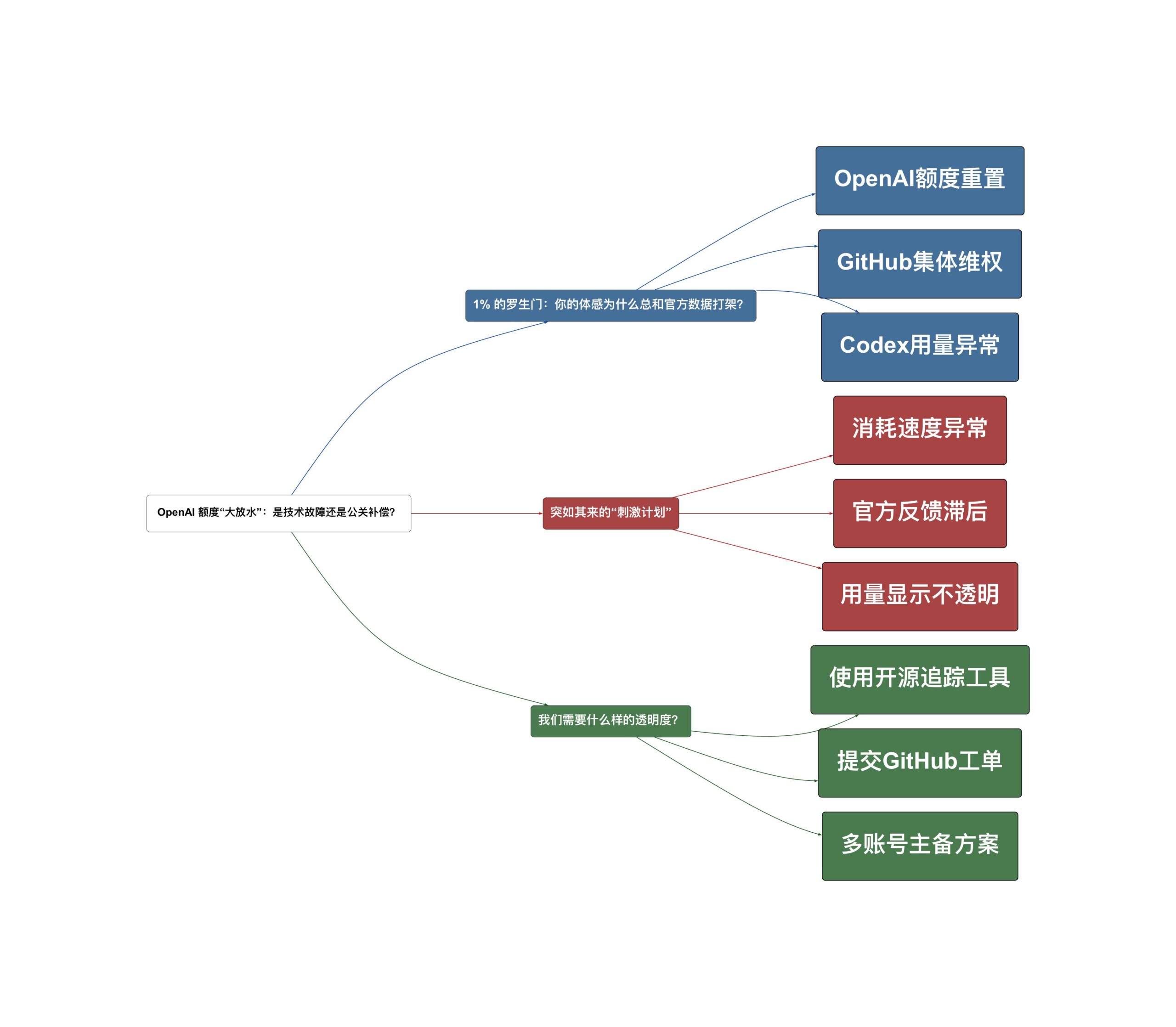
1% 的罗生门:你的体感为什么总和官方数据打架?
整件事的导火索是很多重度用户发现,自己的周额度消耗速度比平时快了 3 到 4 倍。本来能撑一周的工作量,现在半天就提示“额度已满”。
“这绝对不正常,我每天都用 Codex,我太清楚自己的用量了。这绝对不是官方说的增加了 30% 消耗那么简单,简直是 4 倍速在烧。” — Reddit 资深用户
面对满屏的质疑,OpenAI 最初的回复非常“冷淡”,声称只有不到 1% 的用户受影响。但尴尬的是,GitHub 的相关 issue 下面瞬间堆了几百条留言。这种“官方说你没病,你却在咳血”的错觉,让不少付费用户感到被轻视了。
说白了,这种数据统计的滞后或口径差异,在技术圈并不少见。但对于依赖 AI 生产力的开发者来说,这种不透明就是实打实的经济损失。
突如其来的“刺激计划”
也许是 GitHub 上的“千人血书”起了作用,也许是内部确实发现了更严重的 Bug,OpenAI 突然搞了一次全球范围的提前重置。有人戏称这是“Uncle Sam 派发的限额救济金”。
我看到这个消息的第一反应是:这更像是一次低成本的公关危机公关。与其花大量人力去一个个核实谁的账号被多扣了,不如直接按下“全部重置”的红色按钮。虽然简单粗暴,但确实有效平息了怒火。
不过,别高兴得太早。Reddit 上已经有“课代表”反馈,即便重置了,那个消耗异常的 Bug 似乎依然存在:
- 有人刚重置完,一个 prompt 下去就烧掉了 50% 的新额度。
- 这种“重置”治标不治本,如果底层算法的 Token 统计逻辑没修好,大家很快又要陷入下一轮的“额度焦虑”。
我们需要什么样的透明度?
这次风波暴露了一个更深层次的问题:目前 AI 工具的用量显示太像 90 年代的红白机游戏了。你只能看到一个模糊的血条,却不知道每一刀到底砍掉了多少血。
“比起这种像玩《洛克人》一样的血条,我们更需要能看清每一笔开销的详细清单。” — 某开发者评论
对于专业用户来说,我们不怕为服务付费,但我们讨厌“黑盒”。现在的逻辑是:我喂给 AI 一段代码,它反馈结果,然后我的额度就莫名其妙少了一大截。这种不确定性是专业工作流的大忌。
💡 避坑与实操建议
既然官方的透明度还没跟上,开发者只能自救。这里有几个从 Reddit 社区里扒出来的实操建议:
- 使用开源追踪工具:Reddit 上有人开发了像
onwatch这样的开源工具,可以跨平台追踪不同 LLM 供应商的用量。既然官方不给详细数据,我们就自己动手统计。 - 保留 GitHub Issue 证据:如果你的额度真的出现了断崖式下跌,去 OpenAI 的专属 issue 页面留言,并附上你的 User ID。这次的全球重置证明,大规模的社区反馈确实能推动决策。
- 多账号备份方案:不少大神分享了自己同时维护两个 Plus 账号的策略。在目前的阶段,AI 额度的稳定性还远没达到电力或自来水那样的水平,备用方案是生产力的刚需。
这件事之后,你会选择继续信任官方的自动统计,还是会开始寻找第三方的监控方案?评论区聊聊你的看法。
💡 核心洞察: 当官方数据与用户体感产生偏差时,社区反馈是倒逼大厂透明化的核心力量;开发者应建立独立的用量监控意识。
Read the original discussions on Reddit:
- [r/codex] OpenAI says that the abnormal weekly limit consumption affec…
- [r/codex] Weekly limits just got reset early for everyone
- [r/codex] Limit reset?
- [r/codex] Thanks for the limit reset Codex team
- [r/codex] WEEKLY USAGE LIMIT STIMULUS IS HEER